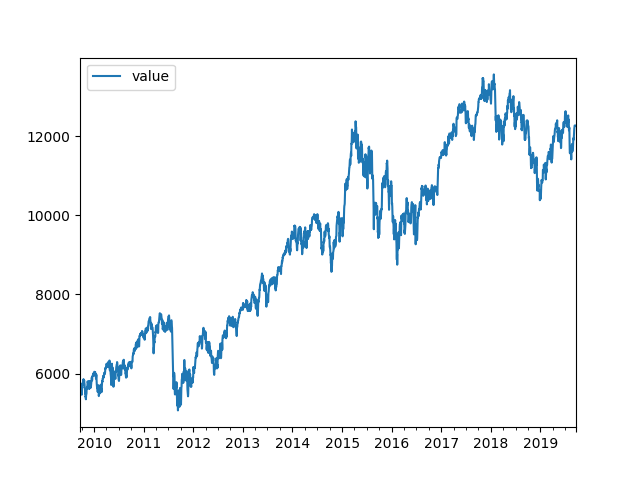
The target is to get some time series data in any currency, multiply it with an FX and store it in EUR. First approach was something like:
- “crawl time series and write in table a”.py everyhour
- “crawl fx time series and write in table b”.py everyhour
- “read table a & read table b, multiply and write in table c”.py everyhour
Everything went well and I came up with the idea: “Could the third step not be done by the MySQL-db itself?”
- “crawl time series and write in table a”.py everyhour
- “crawl fx time series and write in table b”.py everyhour
- table a uses the AFTER INSERT & AFTER UPDATE function to trigger the transformation and storage in table c. As example added the following code to table a:
CREATE DEFINER=wolfgang@localhost TRIGGER raw_cps_AFTER_INSERT AFTER INSERT ON raw_cps FOR EACH ROW BEGIN
IF NEW.currency = 'USD' THEN
SELECT USD FROM investment_db.ts_pivot_currency WHERE date=NEW.date INTO @FX;
SET @value_fx = NEW.value/@FX;
INSERT INTO investment_db.fun_cps (pk, date, value,currency)
VALUES(NEW.pk, NEW.date, @value_fx, 'EUR')
ON DUPLICATE KEY UPDATE value=@value_fx, currency='EUR';
END IF;
END
… and then i noticed that i get an error in my “crawl time series and write in table a”.py. There was data in table a. Conclusion step (1) = ok. Also there was a lot of data in table b and table c. So was step (2) and step (3) = ok. No!
Tight coupling introduced by mistake!
Because of one missing FX entry, the multiplication failed and due to that the error was transferred to the python script. Because the script was running in an container and some quick and dirty programming, it was permanently restarted 😉